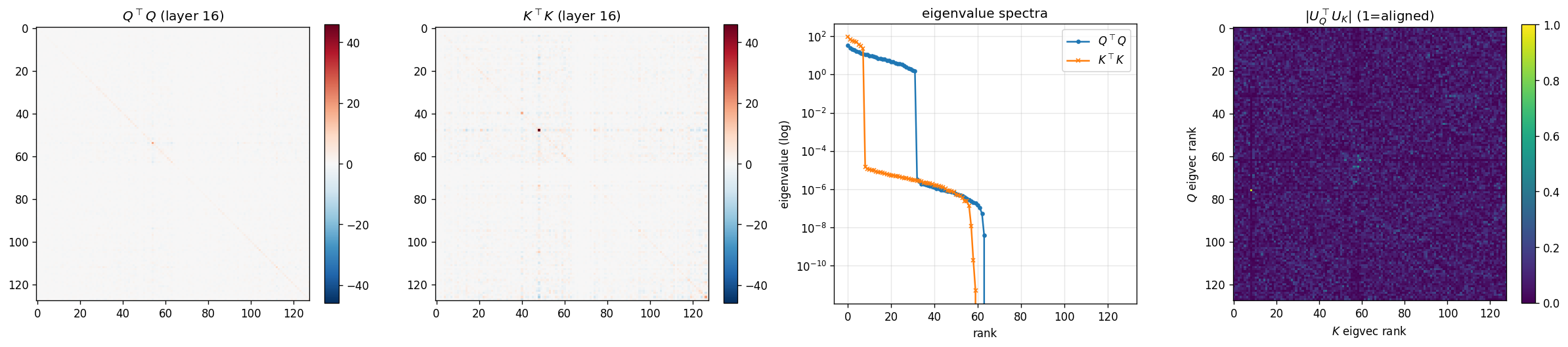
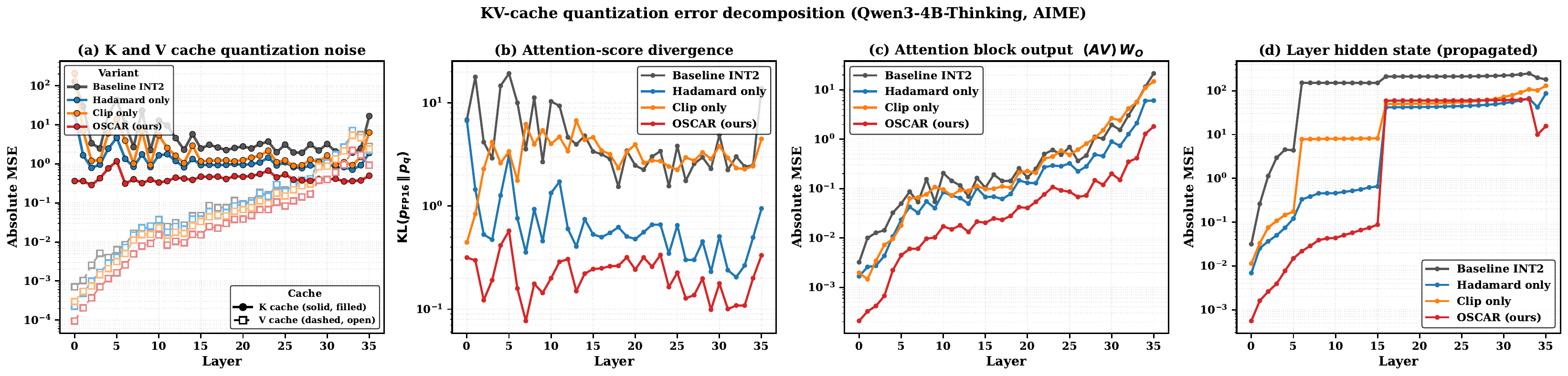
This example uses \(d = 128\), \(G_K = 64\), 8000 calibration tokens, and the production
query covariance averaged over GQA groups. The table separates what the quantizer sees from how attention
weights the resulting residual.
No rotation. One raw token has group ranges \(44.81\) and \(7.19\); a few outliers set
the INT2 scale, so most coordinates in that group are quantized too coarsely.
\(U_Q\) alone. The attention importance is now explicit, but K-side variance is pushed into
the eigenbasis unevenly. In the example, the difficult group flips: the second group range jumps to \(37.85\).
\(U_QH_{\mathrm{Had}}\). Hadamard spreads the spike across all channels and forces
\(\max/\mathrm{mean} = 1.00\) for the diagonal of the importance metric. The per-group ranges become nearly balanced.
\(U_QH_{\mathrm{Had}}P_K\). The permutation does not change the set of 128 values; it changes
which values share an INT2 group. Averaged across tokens, the mean per-group max-min drops from \(13.40\) to
\(11.58\), reducing \(\operatorname{tr}(E_K)\) from \(208\) to \(169\).
What the quantizer sees for one token
Each matrix prints all 128 channels for one non-sink token, reshaped as an \(8 \times 16\) grid.
The horizontal rule separates the two \(G_K=64\) INT2 groups.
No rotation: \(K_{t,\cdot}\)
group 0 range \(44.81\), group 1 range \(7.19\)
\[
{\small
K_{t,\cdot} =
\left[
\begin{array}{rrrrrrrrrrrrrrrr}
3.42 & -0.61 & 1.59 & 0.27 & -3.14 & -0.05 & 3.55 & 1.09 & 2.05 & -1.05 & 1.86 & -0.03 & -0.42 & -0.89 & -1.54 & 2.06 \\
-1.74 & -0.15 & -0.39 & -0.89 & -0.02 & 2.55 & 0.11 & 1.79 & -0.28 & 0.25 & -1.40 & -6.09 & -1.04 & -0.12 & 0.64 & -0.95 \\
9.06 & 1.17 & 0.08 & -1.49 & 0.29 & 1.13 & 0.47 & 0.17 & 1.22 & 0.55 & 14.19 & -0.26 & -0.09 & 0.20 & 2.39 & 0.40 \\
1.09 & -0.06 & \mathbf{-30.62} & 0.00 & 1.03 & 0.57 & -1.30 & 2.47 & -0.11 & -0.08 & 0.56 & -0.47 & 0.45 & -0.88 & 2.31 & -1.05 \\
\hline
0.50 & 0.44 & 0.10 & -0.35 & -0.78 & 1.46 & -1.16 & 2.56 & 1.64 & -0.09 & 0.90 & 2.33 & 1.09 & 2.72 & 0.95 & 0.20 \\
1.30 & 1.82 & 0.54 & 1.27 & -1.05 & 0.50 & -4.47 & 1.20 & 0.32 & 1.36 & -0.81 & -0.04 & 2.27 & -0.77 & 0.64 & 1.27 \\
0.03 & -0.20 & 0.41 & 0.58 & 0.79 & 1.05 & 0.46 & -0.09 & 0.49 & 0.29 & -0.02 & 0.20 & 1.36 & 0.77 & -1.01 & -2.33 \\
1.19 & -1.77 & -0.01 & -0.49 & 0.47 & 0.91 & 0.42 & 0.17 & 1.38 & -0.39 & -0.00 & 0.43 & -0.98 & -0.50 & 0.17 & -0.50
\end{array}
\right]}
\]
Eigenbasis only: \((KU_Q)_{t,\cdot}\)
group 0 range \(7.16\), group 1 range \(37.85\)
\[
{\small
(KU_Q)_{t,\cdot} =
\left[
\begin{array}{rrrrrrrrrrrrrrrr}
0.16 & -1.75 & 1.86 & -2.42 & 1.11 & 1.05 & -0.69 & 0.26 & 1.11 & -0.55 & 3.39 & -1.80 & 1.78 & 1.65 & -1.49 & -1.32 \\
0.05 & -0.18 & -2.00 & -1.27 & 3.20 & -1.47 & 0.31 & -1.07 & 0.87 & -1.54 & -3.78 & -0.89 & 1.60 & 1.03 & 0.50 & 0.55 \\
0.49 & 0.55 & -0.90 & -0.05 & 0.17 & 0.20 & 0.78 & -1.21 & -1.06 & -1.70 & 0.63 & 0.12 & -0.28 & 2.99 & 2.88 & -0.97 \\
-1.42 & 2.12 & -0.94 & -2.88 & 1.30 & -0.42 & 1.37 & 0.58 & -1.46 & -2.04 & 0.28 & -0.28 & -2.63 & -0.20 & -1.77 & -0.83 \\
\hline
0.50 & 0.12 & -1.19 & 0.81 & -1.90 & 0.40 & -1.31 & -0.15 & -2.31 & 1.52 & 3.20 & -0.46 & -0.77 & -0.09 & -1.34 & 1.72 \\
0.40 & -0.72 & -0.57 & 0.40 & 0.84 & -0.72 & -1.94 & -0.11 & 1.26 & 0.07 & 0.09 & -0.06 & 0.87 & -0.92 & -0.63 & 1.19 \\
-2.31 & 1.56 & 1.90 & 1.26 & 1.16 & -0.72 & -0.56 & -0.48 & 1.21 & 0.20 & -0.26 & -1.78 & 1.71 & -1.28 & 1.07 & 1.27 \\
-3.32 & 0.47 & -0.43 & -1.77 & -1.42 & 1.42 & 4.99 & -1.91 & -0.25 & -1.02 & 0.51 & -1.65 & -1.11 & -8.07 & 15.28 & \mathbf{29.77}
\end{array}
\right]}
\]
Eigenbasis + Hadamard: \((KU_QH_{\mathrm{Had}})_{t,\cdot}\)
group 0 range \(13.52\), group 1 range \(13.58\)
\[
{\small
(KU_QH_{\mathrm{Had}})_{t,\cdot} =
\left[
\begin{array}{rrrrrrrrrrrrrrrr}
2.24 & 1.08 & -3.73 & 0.26 & -5.76 & 0.92 & 4.08 & -3.39 & -3.72 & 0.29 & 5.55 & -2.67 & 3.19 & -3.70 & -4.16 & 1.80 \\
-0.87 & 0.64 & 4.12 & -3.18 & 5.12 & 1.16 & -6.79 & 0.97 & 1.91 & -2.08 & -4.91 & 4.21 & -1.67 & 1.97 & 4.47 & -0.63 \\
-2.86 & 0.66 & 6.73 & 1.83 & 4.37 & 1.49 & -5.77 & 0.72 & 1.52 & -0.05 & -4.94 & 3.97 & -3.09 & 2.28 & 4.34 & -0.37 \\
1.90 & -1.30 & -6.06 & -1.90 & -2.58 & 3.27 & 4.18 & -3.10 & -2.31 & 0.88 & 5.04 & -2.61 & -0.07 & -1.10 & -2.17 & 4.09 \\
\hline
-3.71 & 2.31 & 6.89 & -1.79 & 1.12 & -0.12 & -5.61 & 3.44 & 4.10 & 0.85 & -3.94 & 3.17 & -3.51 & 0.62 & \mathbf{7.03} & -5.15 \\
4.11 & 1.23 & -4.84 & 0.19 & -3.60 & 2.16 & 3.36 & -0.01 & -4.31 & 0.17 & 3.97 & -2.02 & 2.49 & -0.04 & -4.11 & 2.57 \\
3.72 & 2.20 & -3.51 & 1.67 & -5.30 & -0.01 & 4.53 & -2.49 & -3.30 & 0.32 & 2.06 & -4.40 & 3.14 & -1.10 & \mathbf{-6.54} & 1.40 \\
-2.85 & 1.72 & 5.21 & -0.32 & 4.97 & 1.00 & -5.68 & -1.24 & 3.87 & -1.45 & -5.40 & 1.67 & -4.30 & 1.20 & 3.73 & -3.39
\end{array}
\right]}
\]
Pure Hadamard: \((KH_{\mathrm{Had}})_{t,\cdot}\)
group 0 range \(13.12\), group 1 range \(14.01\)
\[
{\small
(KH_{\mathrm{Had}})_{t,\cdot} =
\left[
\begin{array}{rrrrrrrrrrrrrrrr}
2.20 & -0.20 & 3.44 & 2.25 & -1.33 & 2.33 & 3.83 & 2.71 & -2.34 & -5.96 & 4.20 & 5.20 & -3.46 & -0.77 & 4.42 & 4.48 \\
\mathbf{7.15} & 5.23 & -4.17 & -3.54 & 5.85 & 5.28 & -3.61 & -1.41 & 1.05 & 3.94 & -1.22 & -2.85 & 1.48 & 1.03 & 2.05 & -0.46 \\
1.02 & -1.19 & -2.61 & -2.01 & 0.93 & 3.00 & -1.01 & -3.19 & 3.09 & 2.20 & -5.85 & -5.58 & 4.90 & 3.06 & -4.39 & -3.55 \\
-3.07 & -3.65 & 0.48 & 4.83 & -3.59 & -2.92 & 3.38 & 5.09 & -2.81 & -0.89 & 1.22 & 0.46 & -3.49 & -2.21 & 2.88 & 0.84 \\
\hline
-1.53 & 1.03 & 0.94 & 0.19 & -2.30 & 0.20 & 5.16 & 1.89 & -1.37 & -3.52 & 4.74 & 4.87 & -3.51 & -4.25 & 4.14 & 5.80 \\
5.48 & 5.35 & -4.44 & -1.88 & 7.12 & 5.46 & -1.44 & -2.71 & 1.37 & 3.77 & 0.45 & -2.59 & 3.21 & 2.03 & -0.67 & 0.81 \\
-1.55 & 2.51 & -2.80 & -3.34 & 0.29 & 1.81 & -2.03 & -0.88 & 5.68 & 4.70 & \mathbf{-6.89} & -5.69 & 1.38 & 1.07 & -4.79 & -2.27 \\
-3.94 & -4.43 & 2.41 & 5.23 & -2.12 & -5.19 & 2.62 & 2.32 & -1.78 & -2.21 & 0.40 & 0.43 & -0.79 & -1.48 & 1.86 & 2.20
\end{array}
\right]}
\]
OSCAR: \((KU_QH_{\mathrm{Had}}P_K)_{t,\cdot}\)
group 0 range \(13.82\), group 1 range \(9.36\)
\[
{\small
(KU_QH_{\mathrm{Had}}P_K)_{t,\cdot} =
\left[
\begin{array}{rrrrrrrrrrrrrrrr}
2.24 & -3.71 & -2.86 & 3.72 & -0.87 & 4.11 & 1.90 & -2.85 & -3.72 & 4.10 & 1.52 & -3.30 & 1.91 & -4.31 & -2.31 & 3.87 \\
-5.76 & 1.12 & 4.37 & -5.30 & 5.12 & -3.60 & -2.58 & 4.97 & 3.19 & -3.51 & -3.09 & 3.14 & -1.67 & 2.49 & -0.07 & -4.30 \\
-3.73 & 6.89 & 6.73 & -3.51 & 4.12 & -4.84 & -6.06 & 5.21 & 5.55 & -3.94 & -4.94 & 2.06 & -4.91 & 3.97 & 5.04 & -5.40 \\
4.08 & -5.61 & -5.77 & 4.53 & -6.79 & 3.36 & 4.18 & -5.68 & -4.16 & \mathbf{7.03} & 4.34 & \mathbf{-6.54} & 4.47 & -4.11 & -2.17 & 3.73 \\
\hline
1.08 & 2.31 & 0.66 & 2.20 & 0.64 & 1.23 & -1.30 & 1.72 & 0.29 & 0.85 & -0.05 & 0.32 & -2.08 & 0.17 & 0.88 & -1.45 \\
0.92 & -0.12 & 1.49 & -0.01 & 1.16 & 2.16 & 3.27 & 1.00 & -3.70 & 0.62 & 2.28 & -1.10 & 1.97 & -0.04 & -1.10 & 1.20 \\
0.26 & -1.79 & 1.83 & 1.67 & -3.18 & 0.19 & -1.90 & -0.32 & -2.67 & 3.17 & 3.97 & -4.40 & 4.21 & -2.02 & -2.61 & 1.67 \\
-3.39 & 3.44 & 0.72 & -2.49 & 0.97 & -0.01 & -3.10 & -1.24 & 1.80 & -5.15 & -0.37 & 1.40 & -0.63 & 2.57 & 4.09 & -3.39
\end{array}
\right]}
\]